

Data classification and protection are today’s biggest challenges
Azure information protection solutions (part of Microsoft Information protection) helps organizations to implement data protection strategies. AIP integration with other Microsoft solutions such as Active Directory, Cloud App Security, M365, etc helps enable additional functionalities to meet the regulatory compliance (such as GDPR), balance data security and enable productivity.
Where do I start ?
In this blog, let’s focus on establishing the foundation of Azure information protection solution. Most customer require detailed understanding on the basics and require guidance on effective planning and implementation of AIP solutions.
1. Getting started with Azure Information Protection License Features & Use cases
Microsoft Azure information protection subscription has three editions of license (refer below figure). Depending on the use-case and functional requirements, customer’s should consider either standalone licenses or through other Microsoft licensing suites.
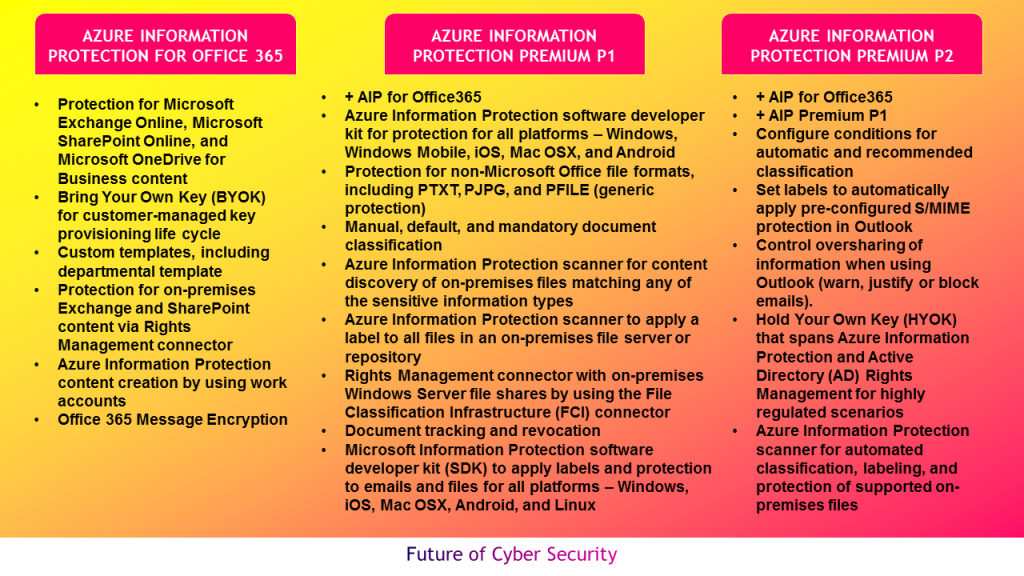
Azure information protection for Office 365 is part of Office 365 enterprise E3 and above plans. Azure information protection premium P1 costs $2 per user additional price to provides additional rights to use the on-premises connectors, track and revoke shared documents and enable users to manually classify and label documents. Azure information protection premium P2 costs $5 per user extra price to provide automated and recommended classification, labeling and protection, with policy-based rules and Hold Your Own Key (HYOK) configurations that span Azure Rights Management and Active Directory Rights Management.
2. Environmental Analysis
It’s important to perform environmental analysis before defining the Azure information protection implementation plan. Use information gathering templates to captures below inputs
- Types of data (unstructured data) – such as emails, files, etc.
- Where is the data – End user devices (laptops, mobiles), SaaS apps, File shares, Exchange online, SharePoint, OneDrive, etc.
- Data classification types – Sensitive personal data, Regulated data
- Current state – Data classification, labeling, protection
- Stakeholders – HR, 3rd party users/ Partners, Data admin, Data Owner, Information worker (who creates documents, emails or other content)
- Data classification taxonomy – Sensitivity labels, Retention labels
- Risk of data – Intellectual property, Financials, Regulated Data
- Visibility and control – analytics and reports over data in its life cycle
- Other security technologies – CASB, DLP, MDM, AD, Key Mgmt.
- Expertise – Do we have subject matter expert to execute AIP project
3. Understand the Azure Information Protection Project Phases
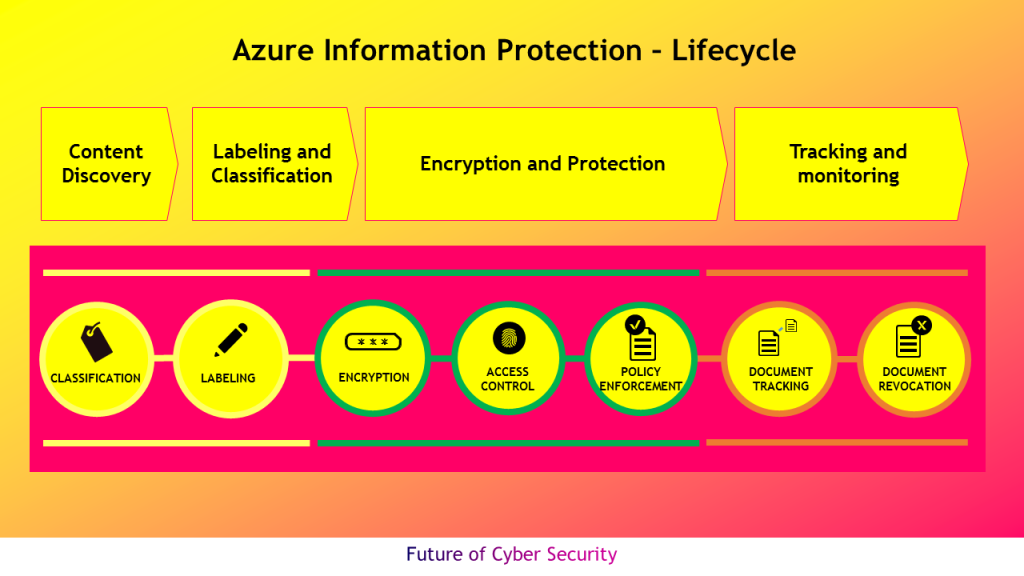
Microsoft Azure Information Protection project has key four phases as depicted in the below diagram that includes detecting sensitive data across variety of locations, classify sensitive data and apply labels to documents and emails – automatically or manually, apply flexible protection protection actions such as encryption, access restrictions and visual markings and to monitor and remediate to have more control over the data.
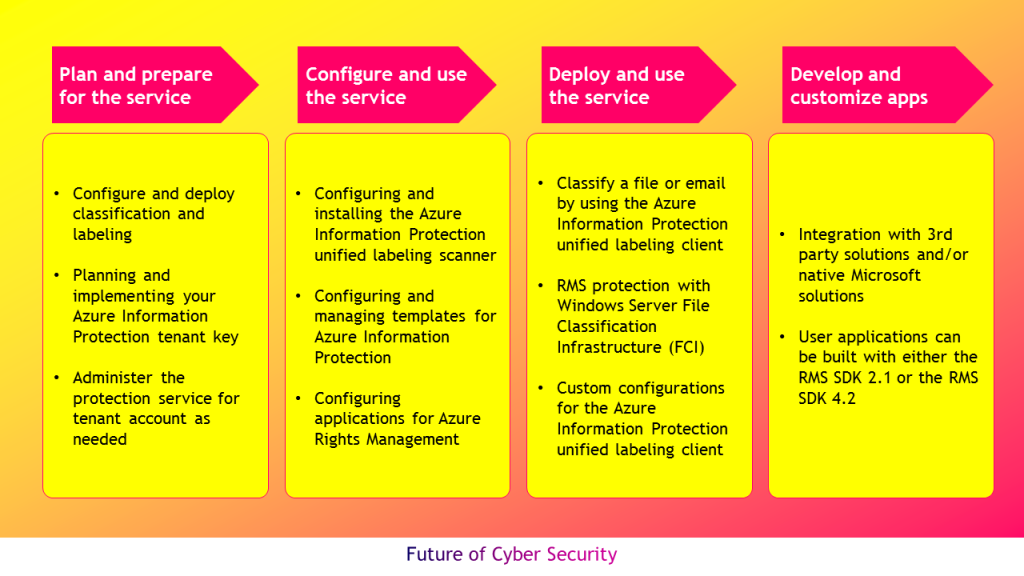
After establishing the tenant, customer should install Azure information protection client that can be used by MacOS, iOS, and Andriod to classify and protect files and emails. This client downloads labels and policy settings from Azure portal. Microsoft recently announced Azure information protection unified labeling client to support unified labeling store that multiple applications and services support. This client downloads labels and policy settings from Office 365 security and compliance center, Microsoft 365 Security center, and Microsoft 365 Compliance center.
Customer can use both of these clients and migrate the labels in the Azure portal so that both set of clients share same set of labels for ease of administration
4. Adopt Azure Information Protection Best Practices
Discovering sensitive data depends on where the data is stored within the organisation.
- Deploy the AIP scanner in the on-premise location, if the data resides only in on-premise repositories (such as CIFS / SMB file shares and SharePoint libraries) and the AIP client to do discovery on windows endpoints.
- Leverage Microsoft Cloud App Security (MCAS) and Office 365 DLP capabilities to do discovery of information residing in various web repositories if organization has moved all its data to the cloud and mandated cloud storage as primary data repository
- Use combination of above points (1) and (2), if organizations have hybrid data management to perform comprehensive discovery of sensitive information
AIP scanner uses the same content matching engine that Office DLP uses and has 90 out-of-the-box sensitive information types. Setup and run the AIP scanner in discovery mode to scan non production data repositories (initially, before doing it in production) to match using custom Regex patterns or plain text phrases. Use recommendation console window after discover is done to classify the data and to create conditions for users to protect data. Start with default AIP data classification taxonomy and apply labels for files. The recommended best practices are listed in the diagram below
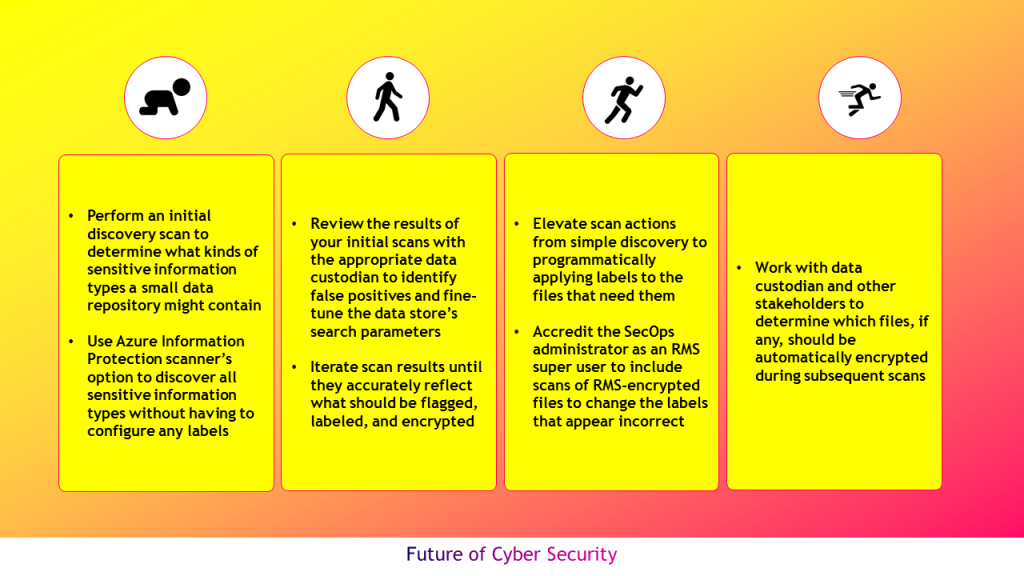
The amount of data is the key factor in deciding when to add additional scanners; the terabytes of data being scanned is a more important determinant than the number of files or shares, or their locations. If Office 365 DLP is currently in use to scan cloud data store, then use them in Azure Information Protection scanner and apply same logic. Consult with data custodians and owners to help identify the most sensitive content that we need to discover, and partner with them throughout our ongoing scan cycles to best protect their sensitive data.





Leave a comment